谷歌翻译不再需要人工建议来改进翻译
Google 翻译在帮助文章中表示已关闭贡献功能。贡献功能 2014 年首次推出时,当翻译没有达到预期时,该功能允许用户点击按钮“改进此翻译”,并编写替代翻译。但随着系统的不断发展和学习, Google 认为翻译质量有了显著的改进,因此将不再提供贡献功能。
谷歌翻译中的评分反馈功能将继续保留,用户可以对翻译结果给出评价。
—— Google 帮助中心
谷歌翻译不再需要人工建议来改进翻译
Google 翻译在帮助文章中表示已关闭贡献功能。贡献功能 2014 年首次推出时,当翻译没有达到预期时,该功能允许用户点击按钮“改进此翻译”,并编写替代翻译。但随着系统的不断发展和学习, Google 认为翻译质量有了显著的改进,因此将不再提供贡献功能。
谷歌翻译中的评分反馈功能将继续保留,用户可以对翻译结果给出评价。
—— Google 帮助中心
OPENAI 的竞争对手 Anthropic 刚刚发布了新模型 Claude 2.1
就在 OpenAI 陷入危机之际,Anthropic 推出了一款新的模型。Anthropic 是一家由谷歌支持的人工智能初创公司,由前 OpenAI 工程师创立。
Anthropic 公司宣布,其聊天机器人 Claude 2.1 的最新更新可以为专业级用户一次消化多达 20 万个 tokens,据称相当于 500 多页的材料。
该公司还表示,Claude 产生幻觉或撒谎的频率只有以前的一半,而且它还能通过可定制的工具完成搜索网页或使用计算器等操作。 聊天机器人现在还支持自定义、持续性的指令,并有一个新的测试窗口用于尝试提示。
—— TheVerge、 Anthropic
Stability AI 发布最新语言模型:Stable LM 3B
Stability AI 发布了其最新语言模型:Stable LM 3B,设计用于在手持设备和笔记本电脑等便携式数字设备上运行。
Stable LM 3B 拥有30 亿个参数(业界通常使用的参数为 70 亿到 700 亿个),是一种紧凑型语言模型。Stable LM 3B 的主要优势之一是其更小的尺寸和更高的效率。与大型模型不同,这些模型需要的资源更少,因此大多数用户都可以轻松使用它们。
与之前的稳定 LM 版本相比,该版本在保持了快速的执行速度的同时,在生成文本方面明显更好。在常见自然语言处理基准测试(包括常识推理和常识测试)中,它的的下游性能得到了提高。
—— Stability AI

OpenAI 发布自然语言图像生成模型 DALL·E 3
DALL·E 3 原生构建在 ChatGPT 上,你可以与 ChatGPT 沟通来进行内容的详细定制。这一点与完全基于 CLIP (图像-文本映射模型) 的其它图像生成AI截然不同,DALL·E 3 有着真正的”思考推理大脑”,这使它对画面的细节有着相当大的掌控力,并且不再需要复杂的 prompt 工程即可理解你的想法。
—— OpenAI
硅谷圈黑客爆料 GPT-4 参数
在AI博客节目 Latent Space 上,George Hotz (iPhone 和 PS3 破解第一人) 爆料 GPT-4 其实只比1750亿参数的 GPT-3 大一些,任何人都能用8倍资金得到它。
GPT-4 是一个8路混合模型,由8个2200亿参数的专家模型组合而成,OpenAI 使用了不同数据训练了同一个模型8次,然后用了一些技巧使它实际做了 16-iter 推理,混合模型是在没有新想法时所会做的。
—— Latent Space
马云支持蚂蚁金服开发AI模型
马云支持的蚂蚁集团正在开发大语言模型技术,为 ChatGPT 类服务提供支持,加入寻求在下一代人工智能领域赢得优势的中国公司行列。
名为“Zhen Yi”的项目正在由一个专门的部门创建,并将部署内部研究。蚂蚁金服发言人证实了这一消息,该消息由星空网率先报道
蚂蚁金服正在与其关联公司阿里巴巴集团控股有限公司、百度公司和商汤科技集团公司等公司展开竞争。他们的努力反映了美国的发展,Alphabet Inc. 的谷歌和微软公司正在探索生成人工智能,它可以从中创建原创内容只需简单的用户提示,即可将诗歌转化为艺术。
人工智能已经成为中美科技竞争的下一个大舞台,引发了人们对中国企业能否长期获得开发大规模人工智能模型所需的高端芯片的担忧。
—— 彭博社
研究表明用AI产生的语料来训练AI将使其退化并最终崩溃
现在,随着越来越多的人使用 AI 来制作和发布内容,一个明显的问题出现了:当 AI 生成的内容在互联网上激增并且 AI 模型开始用其进行训练,而不是使用主要人类生成的内容时,会发生什么?
来自英国和加拿大的一组研究人员已经研究了这个问题,并且最近在开放获取期刊 arXiv 上发表了一篇关于他们工作的论文。他们的发现令当前的生成式 AI 技术及其未来令人担忧:“我们发现在训练中使用模型生成的内容会导致生成的模型出现不可逆转的缺陷。”
研究人员专门研究了文本到文本和图像到图像 AI 生成模型的概率分布,得出结论:“从其他模型生成的数据中学习会导致模型崩溃——一个退化过程,随着时间的推移,模型会忘记真正的底层数据分布……这个过程是不可避免的,即使对于具有近乎理想的长期学习条件的情况也是如此。”
“随着时间的推移,生成数据中的错误会复合并最终迫使从生成数据中学习的模型进一步错误地感知现实,”该论文的主要作者之一 Ilia Shumailov 在给 VentureBeat 的电子邮件中写道。“我们惊讶地观察到模型崩溃发生的速度有多快:模型可以迅速忘记他们最初从中学习的大部分原始数据。”
换句话说:当 AI 训练模型接触到更多 AI 生成的数据时,它的性能会随着时间的推移而变差,在其生成的响应和内容中产生更多错误,并在其响应中产生更少的非错误多样性。
—— VentureBeat
额外编辑:研究人员同样担忧,目前互联网上AI生成内容正在迅速增加,训练下一代ai的数据正在被迅速污染。
stable diffusion 3即将开源
stabilityai CEO Emad 宣布Stable Diffusion 3 即将发布,并开源!有23亿参数,是上一代的2.5倍。
网友称,百度文心绘图会出现质的提升
#SD
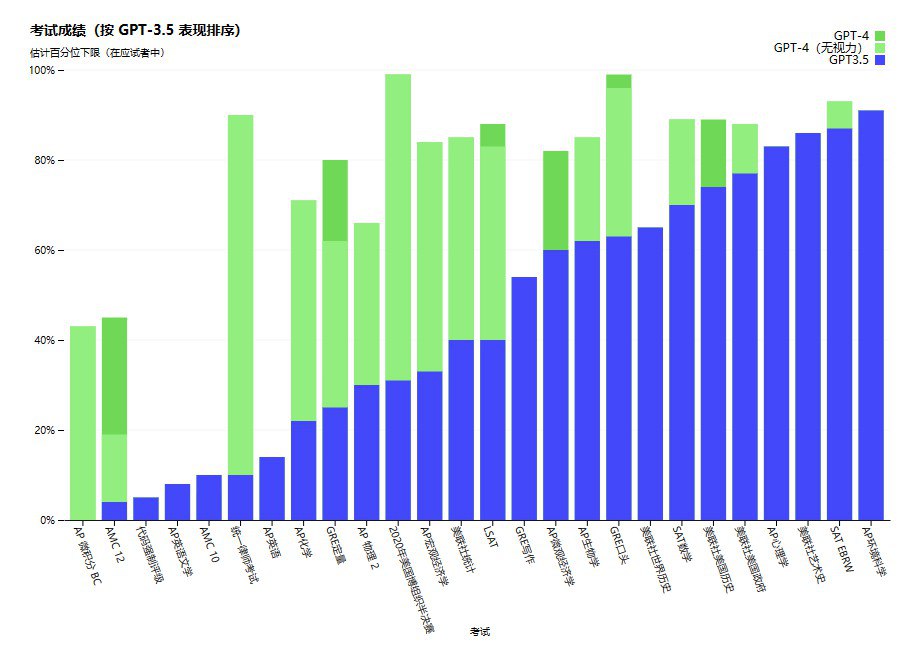
OpenAI 发布新一代大型多模态模型 GPT-4
GPT-4 是一个大型多模态模型,可以接受文本和图像输入。GPT-4 在各种专业学术基准上有着人类水平表现,例如模拟律师考试中,GPT-4 的得分约为前10%,而 GPT-3.5 的得分约为倒数10%。
在多语言测试中,GPT-4 优于 GPT-3.5 和 Chinchilla (来自DeepMind) 还有 PaLM (来自谷歌) ,包括英语性能还有拉脱维亚语、威尔士语和斯瓦希里语等低资源语言。
OpenAI 还开放了角色扮演和性格定制能力,开发人员和用户可以自定义他们的AI风格,而不是具有固定冗长、语气和风格的经典 ChatGPT 个性。
ChatGPT Plus 订阅用户现可直接使用 GPT-4 ,未来将对免费用户开放一定数量的 GPT-4 体验。GPT-4 API 需要申请候选名单,每1k prompt tokens 的价格为$0.03,每1k completion tokens 的价格为$0.06。目前图像输入处在研究预览阶段,仅对少部分客户开放。
微软在 GPT-4 发布后也正式确认 Bing Chat 基于 GPT-4 运行,同时 Bing Chat 的 Edge 边栏功能上线。与数据停留在2021年9月的 GPT-4 离线版本不同,Bing Chat 可联网获取实时信息并且免费。
—— OpenAI
OpenAI 发布产品 AI Classifier,能分辨人类与AI生成的文本
AI Text Classifier 是一个用于区分AI文本和人类文本的分类器,使用了大量针对同一话题的AI文稿和人类文稿进行数据训练。
OpenAI 强调他们的分类器不完全可靠并列举出目前 AI Text Classifier 的局限性:
1. 在低于1000个字符的短文本上非常不可靠。更长文本有时也会被错误标记。
2. 有时会错把人类文本标记为AI文本。
3. 在英文以外语言的文本上表现很差。
4. 无法可靠地识别非常可预测文本。
(例: 无法辨别“前1000个素数的列表”来自AI还是人类,因为答案总是相同)
5. 经人类编辑后的AI文本可以规避分类器。
(分类器可在成功判断的基础上进行更新与再训练)
6. 基于神经网络的AI对其训练集之外的数据校准得不好,分类器有时对与训练集差异较大的输入会得出十分确信但却错误的判断。
查看该产品主页