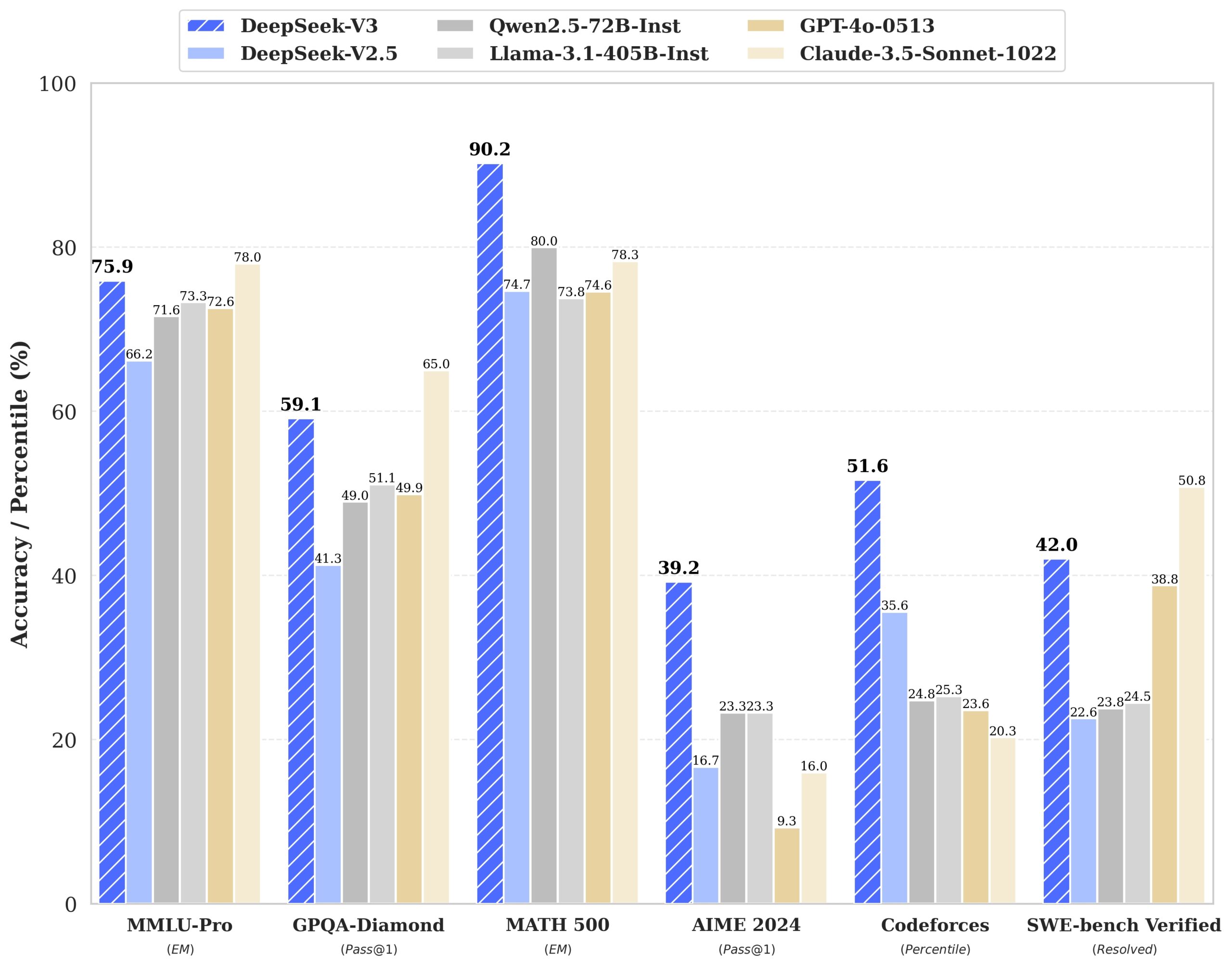
微软推出BitNet b1.58 LLM家族,这是首个超过20亿参数的开源原生1-bit大语言模型。该模型专为高效运行而设计,在内存占用和能耗方面表现优异,尤其适合在CPU或小型硬件设备上执行。
BitNet b1.58系列基于4TB规模的数据集进行训练,具备4096 token的上下文长度。其3B和3.9B版本分别仅需2.22GB和2.38GB内存,相较于LLaMA-3B的7.89GB内存占用显著减少。此外,在延迟性方面,BitNet b1.58-3B/3.9B版本分别仅需1.87ms和2.11ms,优于LLaMA-3B的5.07ms表现。在PPL(困惑度)和零样本训练准确性等关键指标上,BitNet也展现出超越LLaMA-3B的优势。
这一突破标志着大语言模型在终端设备上的应用迈出了重要一步。微软亚洲研究院的相关技术探索,如T-MAC、Ladder和LUT架构,为实现更高效的大规模模型提供了方向。随着技术的进一步发展,未来有望在终端侧支持更大参数规模的AI模型运行,从而推动人工智能技术的实际落地与广泛应用。