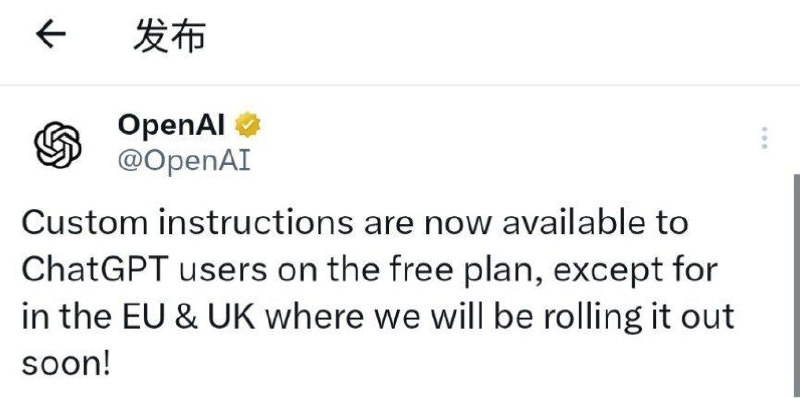
Google Photos 推出由人工智能提供支持的“回忆”选项栏
Google Photos 推出了一种新的方式来重温和分享你最难忘的时刻。你可以在“照片”应用底部新的导航菜单中找到“回忆”视图。
除了构建你自己的回忆时间线之外,你还可以邀请朋友和家人在你创建的回忆视图上进行协作,将他们自己喜欢的照片和视频添加到集合中,类似于共享相册。
新的“回忆”选项视图今天开始向美国用户推出,并将在未来几个月扩展到全球市场。
—— 谷歌博客
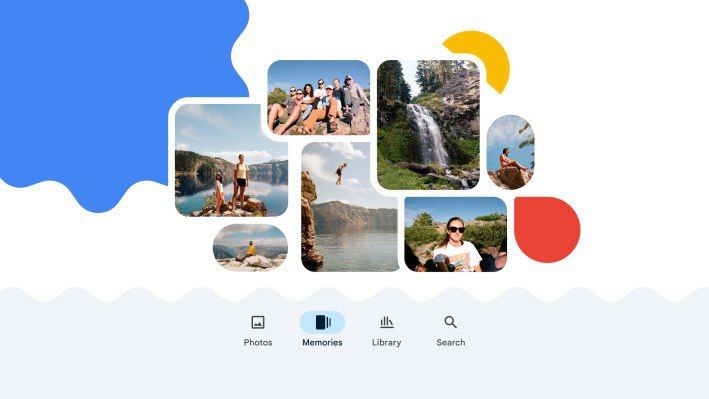
Google Photos 推出由人工智能提供支持的“回忆”选项栏
Google Photos 推出了一种新的方式来重温和分享你最难忘的时刻。你可以在“照片”应用底部新的导航菜单中找到“回忆”视图。
除了构建你自己的回忆时间线之外,你还可以邀请朋友和家人在你创建的回忆视图上进行协作,将他们自己喜欢的照片和视频添加到集合中,类似于共享相册。
新的“回忆”选项视图今天开始向美国用户推出,并将在未来几个月扩展到全球市场。
—— 谷歌博客
OpenAI 相信它的技术可以帮助解决科技领域最难的问题之一:大规模的内容审查。
OpenAI声称,GPT-4 可以取代成千上万名人类审查员,准确度几乎一样且更加一致。如果这是真的,那么科技领域中最具有精神压力和心理伤害的任务可能会被外包给机器。
在一篇博文中,OpenAI 声称已经在使用 GPT-4 来开发和完善自己的内容政策、对内容标记和做出决策。
OpenAI 安全系统负责人 Lilian Weng 告诉 Semafor 说:“我希望看到更多的人以这种方式运作他们的信任和安全以及审查工作。这是我们利用人工智能解决现实世界问题迈出的重要一步,这种方式对社会是有益的。”
与传统的内容审核方法相比,OpenAI 认为有三大优势。首先,不同的审查员对政策的理解是不同的,而机器的判断是一致的。平台审查政策可能会很长,而且不断变化。人类需要经过大量学习才能适应,而 OpenAI 认为大型语言模型可以立即执行新政策。
其次,据称 GPT-4 可以在数小时内帮助制定新政策。起草、标注、收集反馈和完善的过程通常需要数周或数月的时间。第三,OpenAI 提到了长时间接触有害内容(如虐待儿童或酷刑视频)的工人的心理健康问题。
—— The Verge
北京试图在不打压中国人工智能行业的情况下对其进行监管
最终的法规比四月份的最初草案要宽松一些,但它们表明中国和欧洲一样,正在推进政府对过去 30 年来最有前景、也最有争议的技术的监督。相比之下,即使行业领袖警告人工智能带来“灭绝风险”,并且 OpenAI 的萨姆·奥尔特曼 (Sam Altman)在公开听证会上敦促国会参与其中,美国也没有认真考虑立法。
“中国起步很快,”卡内基国际和平基金会研究员马特·希恩(Matt Sheehan)说,他正在就此主题撰写一系列研究论文。“它开始建立监管工具和监管力量,因此他们将做好更充分的准备来监管更复杂的技术应用。”
“在全球激烈竞争的背景下,不发展是最不安全的,”中国政法大学学者张在谈到该指导方针时写道。
在今年的一系列活动中,阿里巴巴、百度和商汤科技都展示了人工智能模型。商汤科技首席执行官徐立完成了最华丽的演示,其中包括一个可以根据英文或中文提示编写计算机代码的聊天机器人。
乔治城安全与新兴技术中心主任海伦·托纳表示:“中国正试图在几个不一定兼容的不同目标之间走钢丝。”
在美国,即使信息是危险的或不准确的,OpenAI 也几乎没有表现出对信息进行控制。
在中国,企业必须更加小心。今年二月,总部位于杭州的远语智能在推出ChatYuan服务几天后就终止了服务。根据网上流传的截图,该机器人称俄罗斯对乌克兰的袭击是一场“侵略战争”,这违反了北京的立场,并对中国的经济前景提出了质疑。
现在,这家初创公司完全放弃了 ChatGPT 模型,转而专注于名为 KnowX 的人工智能生产力服务。“机器无法实现100%过滤,”该公司负责人徐亮说。“但你能做的就是在模型中加入爱国主义、守信和谨慎等人类价值观。”
—— 彭博社
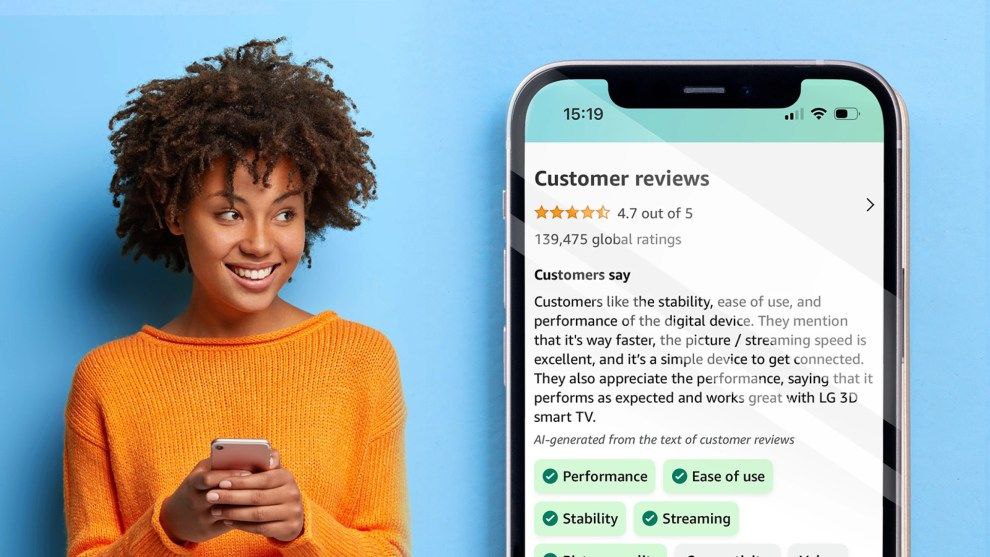
亚马逊添加了人工智能生成的评论摘要,以增强产品体验
亚马逊正在利用人工智能,让人们更容易了解产品。该公司目前正在推出人工智能生成的评论摘要,将成百上千条真实用户的亚马逊评论归纳成一段话,说明大多数人喜欢或不喜欢某件产品的哪些方面。
这些摘要已经测试了至少几个月,现在已在亚马逊的移动应用程序上向美国部分用户提供。
除了摘要文字外,亚马逊还将产品属性做成了可点击按钮。例如,如果客户想了解产品的“易用性”或“性能”,他们就可以点击一个按钮来查看提及这些术语的评论。
—— The Verge
纽约时报禁止使用其内容来训练人工智能模型
《纽约时报》已采取先发制人的措施,阻止其内容被用于训练人工智能模型。据 Adweek 报道,《纽约时报》于 8 月 3 日更新了服务条款,禁止将其内容(包括文字、照片、图像、音频/视频剪辑、“外观和感觉”、元数据或汇编)用于开发“任何软件程序,包括但不限于训练机器学习或人工智能(AI)系统。”
更新后的条款还规定,未经出版物的书面许可,不得使用旨在使用、访问或收集此类内容的网站爬虫等自动化工具。《纽约时报》表示,拒绝遵守这些新限制可能会导致未具体说明的罚款或处罚。尽管在其政策中引入了新规则,但该出版物似乎并未对其 robots.txt 进行任何修改,该文件用于告知搜索引擎爬虫哪些 URL 可以访问。
—— The Verge
ChatGPT 的编程问题正确率比抛硬币还低
普渡大学的一项研究显示,OpenAI 的聊天机器人 ChatGPT 在回答软件编程问题时,有一半以上的时间会回答错误。尽管如此,该机器人的说服力足以骗过三分之一的参与者。
普渡大学团队分析了 ChatGPT 对 517 个 Stack Overflow 问题的回答,以评估 ChatGPT 回答的正确性、一致性、全面性和简洁性。美国学者还对答案进行了语言和情感分析,并就模型生成的结果询问了十几名志愿参与者。
“我们的分析表明,52% 的 ChatGPT 答案是错误的,77% 是冗长的,”该团队的论文总结道。“尽管如此,ChatGPT 答案仍有 39.34% 的时间因其全面性和清晰的语言风格而受到青睐。”
“在研究过程中,我们观察到,只有当 ChatGPT 答案中的错误很明显时,用户才能识别出错误,”论文中说到。“然而,当错误不容易验证或需要外部 IDE 或文档时,用户往往无法识别错误或低估答案的错误程度。”
论文称,即使答案存在明显错误,12 名参与者中仍有两人将答案标记为首选。
—— Theregister 、 论文
研究发现:用人工智能生成的图像训练出的人工智能产生了糟糕的结果。
斯坦福大学和莱斯大学的研究人员发现,生成式人工智能模型需要“新鲜的真实数据”,否则输出的质量就会下降。
这对摄影师和其他创作者来说是个好消息,因为研究人员发现,训练数据集中的合成图像会放大人工痕迹,使人工智能画出的人类看起来越来越不像真人。
研究小组将这种状况命名为“模型自噬障碍”。如果自噬循环的每一代都没有足够的新鲜真实数据,未来的生成模型注定会逐渐降低其质量或多样性。
如果该研究论文是正确的,那么这意味着人工智能将无法开发出无穷无尽的数据源。人工智能仍然需要真实、高质量的图像来不断进步,而不是依赖自己的输出。这意味着生成式人工智能将需要摄影师。
—— petapixel
多家新闻机构签署并发布了一封公开信,呼吁提高人工智能的透明度并加强版权保护。
多家媒体组织呼吁制定规则,保护用于训练生成人工智能模型的数据的版权。
这封公开信敦促全球立法者考虑制定法规,要求训练数据集透明,并在使用数据进行训练前征得权利人的同意。他们还要求允许媒体公司与人工智能模型运营商进行谈判,识别人工智能生成的内容,并要求人工智能公司消除其服务中的偏见和错误信息。
这些签署者表示,使用媒体内容训练的基础模型在传播信息时“完全没有考虑原始创作者的报酬或归属”。
信中写道:“这种做法破坏了媒体行业的核心商业模式,这些模式是建立在读者和观众(如订阅)、许可和广告基础上的。”“除了违反版权法之外,由此产生的影响还减少媒体的多样性,并削弱公司投资媒体报道的财务可行性,进一步降低公众获取高质量和可信任信息的途径。”
—— theverge