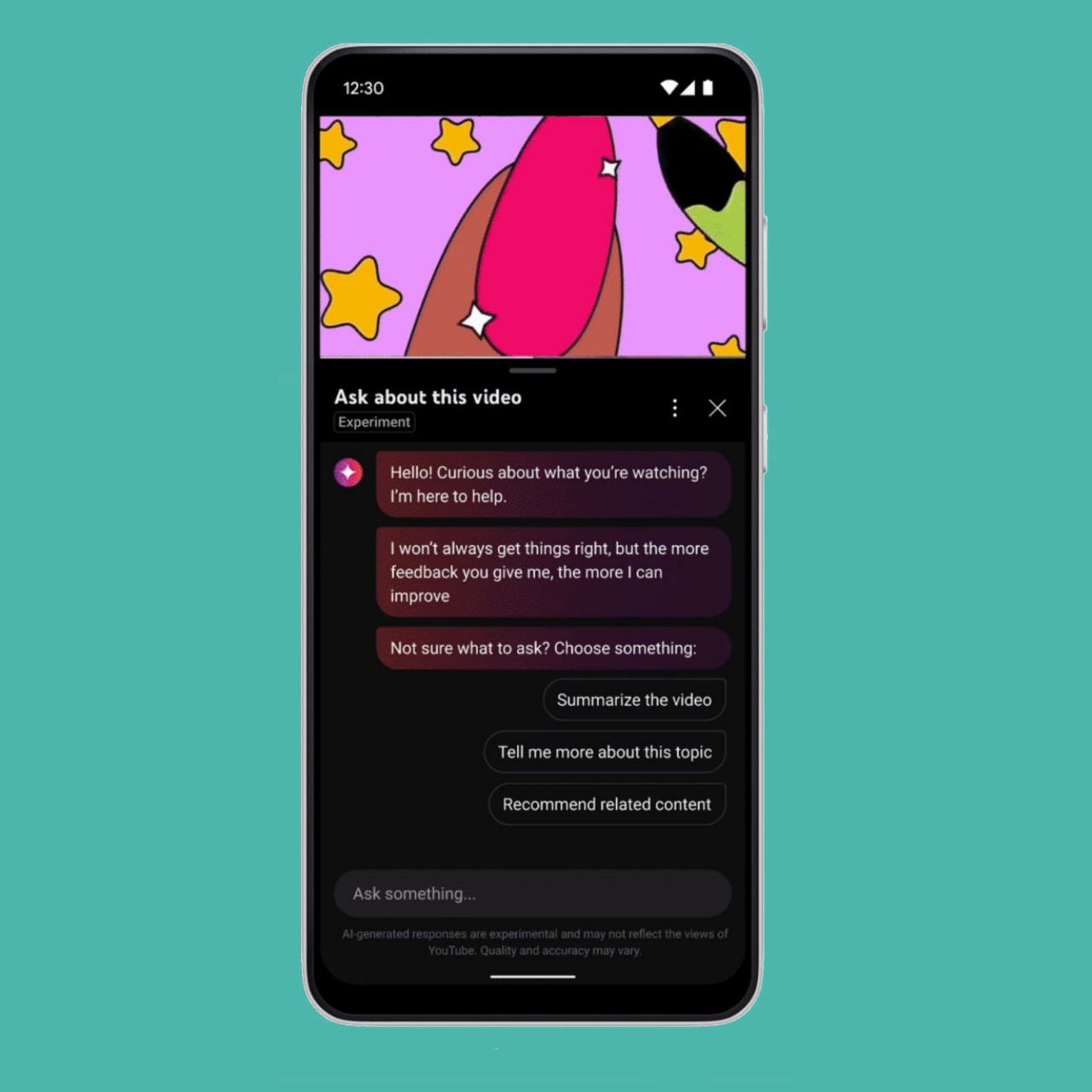
ChatGPT 的语音功能现向所有免费用户开放
ChatGPT 的语音功能现已免费向所有用户开放。在 X 上的一篇推文中,OpenAI 宣布用户现在可以点击耳机图标,在移动应用中使用语言与 ChatGPT 对话,并获得语音回应
今年 9 月,OpenAI 首次推出了用语音和图像提示 ChatGPT 的功能,但该功能只对付费用户开放。
在推文示例中,OpenAI 还对近期发生的事情开了一个笑话,有人问 ChatGPT:“团队度过了一个漫长的夜晚,我们都饿了。 我应该为 778 人点多少份 16 英寸的披萨?” 这个人数与 OpenAI 员工人数大致一样,其中大部分人已签署公开信,要求解散董事会,不然就辞职。
—— Theverge 、OpenAI (提示:API 和 ChatGPT 刚刚出现了故障)