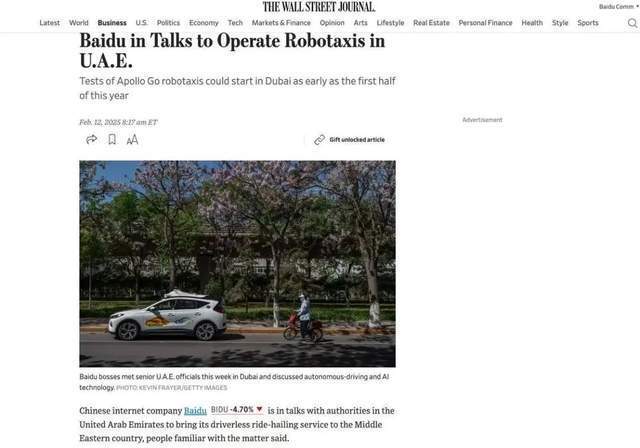
-
华为高管或牵涉向欧盟议员行贿案
华为高管或牵涉向欧盟议员行贿案 比利时司法部门近日透露,正在调查一起涉及华为的腐败案件,指控一名华为说客涉嫌向 [&he…
-
SpaceX为东南亚地震灾区提供星链终端套件支持
SpaceX团队宣布将为缅甸和泰国地震灾区提供星链终端套件以支持灾后通信需求和救援工作。此次强震发生于3月28 [&he…
华为高管或牵涉向欧盟议员行贿案 比利时司法部门近日透露,正在调查一起涉及华为的腐败案件,指控一名华为说客涉嫌向 [&he…
SpaceX团队宣布将为缅甸和泰国地震灾区提供星链终端套件以支持灾后通信需求和救援工作。此次强震发生于3月28 [&he…